
この記事について
本記事は、2023年5月に社内で実施した勉強会の内容を基に、社外向けに再編集したものです。
記載の内容は執筆当時の情報であり、現在の仕様やベストプラクティスと異なる可能性があります。
実装にあたっては、必ず最新の公式ドキュメントをご確認いただくようお願いいたします。
はじめに
システム運用において、本番環境での障害対応は避けられないものです。
本記事ではその経験を踏まえ、リモート環境における本番障害対応時のコミュニケーション上の課題と、その解決策について整理します。
目次
障害対応の基本
障害の検知
- エラートラッキングツールからの通知(例:Rollbar)
- お客様からの報告
- 内部発見
障害対応の流れ
- 障害の検知
- 調査
- 業務への影響調査(ユーザ目線でどのような事象が発生しているか)
- 影響範囲の調査(対象ユーザ数など)
- 原因調査(なぜ障害が発生しているのか)
- 影響期間の調査(いつから障害が発生しているか)
- 対応方法の調査(PGリリース、データパッチのクエリなど)
- 横展開調査
- (Rollbar通知や内部発見の場合)障害報告
- 対応方針検討
- 復旧対応
- 恒久対応
(「5. 復旧対応」がデータパッチなどの暫定対応だった場合は、改めて恒久的な解決策を実施)
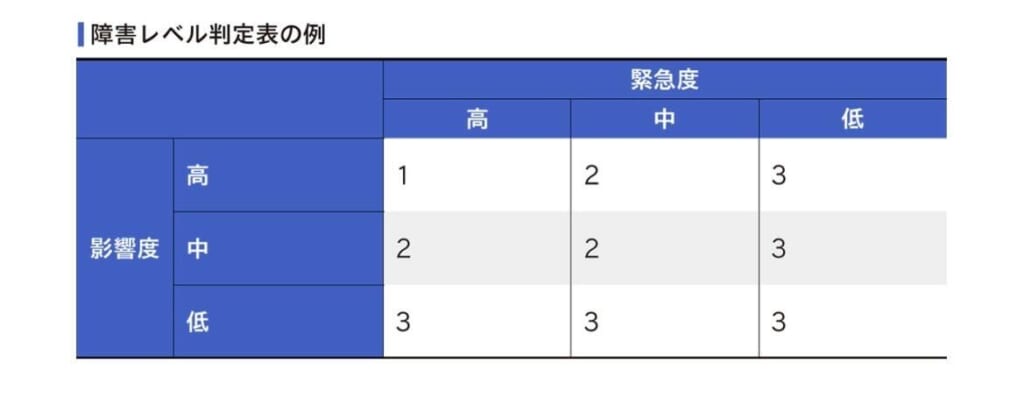
障害レベル
障害が発生した場合、その障害レベルに応じて納期感を判断する必要がある。
参考文献:木村 誠明『システム障害対応の教科書』

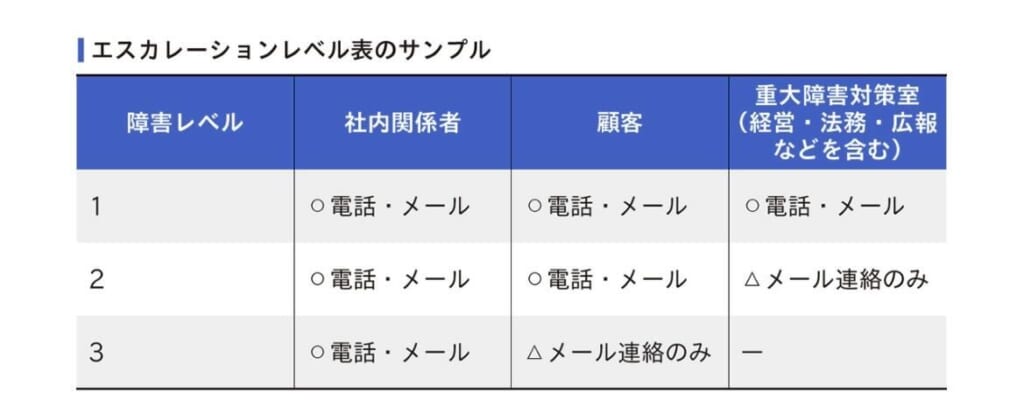
- プロジェクト単位で障害を受ける窓口を決める
- 障害発生時の連絡フローを決める
リモートにおける障害時コミュニケーションの問題点
問題点その1 メンバーが障害対応中であることが把握しづらい
- 解決策1:slackのステータスを「障害対応中」に変更する
- 解決策2:障害対応が発生した際には、チームメンバー全体に共有(メンション)する
メリット
- 主対応者以外の人に知見や心当たりがある場合にフォローしてもらいやすい
- 障害対応以外の作業を主対応者以外がフォローしやすい
- プログラム修正のリリースが発生する場合、急ぎのレビュー依頼に備えやすい
問題点その2 slackは結論の情報をまとめづらい
- 結論としてまとめるべき情報
- TODO(誰が、いつまでに、何をするのか)+リアルタイムでの進行状況
※リモートだと障害に対する緊急度が共有されにくいため、納期感を明確に伝えるのが重要だと感じました。 - 調査結果(+調査に使用したクエリ、ログ、問題となったソースなど)
- 対応方針(PGリリース、データパッチ)
- データパッチ用のクエリ
- TODO(誰が、いつまでに、何をするのか)+リアルタイムでの進行状況
Slackに調査内容を逐次コメントしても、その後のやり取りで情報が流れてしまい整理しづらい。
→ リアルタイムの情報共有はslack、結論の情報は別ツールを使用するのが良いのではないかと思いました。
ツール検討
- backlog
- メリット:
過去の対応などを調べるにあたってまずはbacklogを検索する流れになるので、将来的に情報に辿り着きやすい。
→ 1人で対応している場合や、緊急性がさほど高くない場合は適していると考える。 - デメリット:
リアルタイムに複数人で更新するのに向いていない。
- メリット:
- Googleドキュメント
- メリット:
リアルタイムに複数人で更新できる。
目次が勝手に作られて情報に飛びやすい。 - デメリット:
SQLのフォーマットを綺麗に表示するのとかが面倒くさい。
- メリット:
- Notion (実運用での利用経験は未確認)
- メリット:
リアルタイムに複数人で更新できる。
SQLのフォーマットを綺麗にまとめられる。 - デメリット:現時点では大きな課題は未確認。
- メリット:
おまけ
参考書籍で出てきた障害対応用語など
- インシデントコマンダー
障害対応における現場リーダー。
障害発生時は全ての情報をインシデントコマンダーに集約することが大事。 - ポテンヒット 人と人の間にタスクが落ちてしまい誰もやっていないこと。
- ポストモーテム
システム障害の振り返り。
根本原因や改善策、教訓について話し合う。 - War Room
作戦会議室を指す用語で、障害対応時の集中的な議論に用いられるほか、新規事業のアイデア出しなどでも活用されます。
オンライン上でもホワイトボード形式で情報を整理できるツールが提供されています。




管理-300x158.png)


