
DR対策とは
DR対策とは、災害や障害が発生し、システムやデータが利用できなくなった際に、迅速な復旧と業務継続を実現するための仕組みです。
AWS環境では、複数リージョンに同じ環境を構築し、データのレプリケーションを行う方法が一般的です。
DR用語
RPO(Recovery Point Objective) データ損失の許容範囲を時間で表したもの。
例:「過去1時間分のデータ損失まで許容」
RTO(Recovery Time Objective) システム停止から復旧までの許容時間。
例:「4時間以内に復旧」
DRの種類
各戦略の特徴
| 項目 | コールドスタンバイ | パイロットライト | ウォームスタンバイ | ホットスタンバイ |
|---|---|---|---|---|
| 概要 | 全システムが停止状態で待機 | 最小限のコアシステムのみ稼働 | 一部システムが稼働状態で待機 | 全システムが稼働状態で待機 |
| システム稼働状態 | 全て停止 | データベースなど重要部分のみ稼働 | 縮小版システムが稼働 | 本番同等のシステムが稼働 |
| データ同期 | 定期的なバックアップのみ | リアルタイムまたは準リアルタイム | 継続的なデータ同期 | リアルタイム同期 |
| 災害時の復旧手順 | 全システム起動 + データ復旧 | 残りシステムの起動 + スケールアップ | システム拡張 + 切り替え | 即座に切り替え |
運用特性
| 項目 | コールドスタンバイ | パイロットライト | ウォームスタンバイ | ホットスタンバイ |
|---|---|---|---|---|
| RTO(復旧時間) | 数時間~数日 | 数十分~数時間 | 数分~数十分 | 数秒~数分 |
| RPO(データロス) | 数時間~1日 | 数分~数時間 | 数分~数十分 | 数秒~数分 |
| 初期コスト | 低 | 中 | 中~高 | 高 |
| 運用コスト | 低 | 中 | 中~高 | 高 |
| 複雑性 | 低 | 中 | 中~高 | 高 |
使用場面
| 戦略 | 適用業界・システム | 具体例 |
|---|---|---|
| コールドスタンバイ | 非クリティカルシステム | 社内システム、開発環境 |
| パイロットライト | 中小企業の基幹システム | 中規模ECサイト、業務アプリ |
| ウォームスタンバイ | 重要だが一時停止可能なシステム | 企業Webサイト、顧客管理システム |
| ホットスタンバイ | ミッションクリティカルシステム | 金融システム、医療システム、大規模ECサイト |
プロジェクトAで行った事例
プロジェクトAでは、以下の方針でDR対策を検討しました。
- 想定リスク:大規模地震などで東京リージョンが利用不可になるケース
- 採用戦略:パイロットライト方式
- ソウルリージョンに東京リージョン同等のインフラを構築
- DB系のデータ層は常時稼働し、レプリケーションを実施
- STG環境で移行・稼働テストを完了(本番構築は今後実施予定)
切り替え対象のAWSサービス
- ECS
- EC2
- ALB
- Aurora DB
- ElastiCache
- APIGateway
- CloudFront
- Lambda
- Route53
- EventBridge
- S3
以下、構築のみ。切り替え対応不要。
- WAF
- SystemManager
- SQS
- CloudWatch
- SNS
- Bedrock
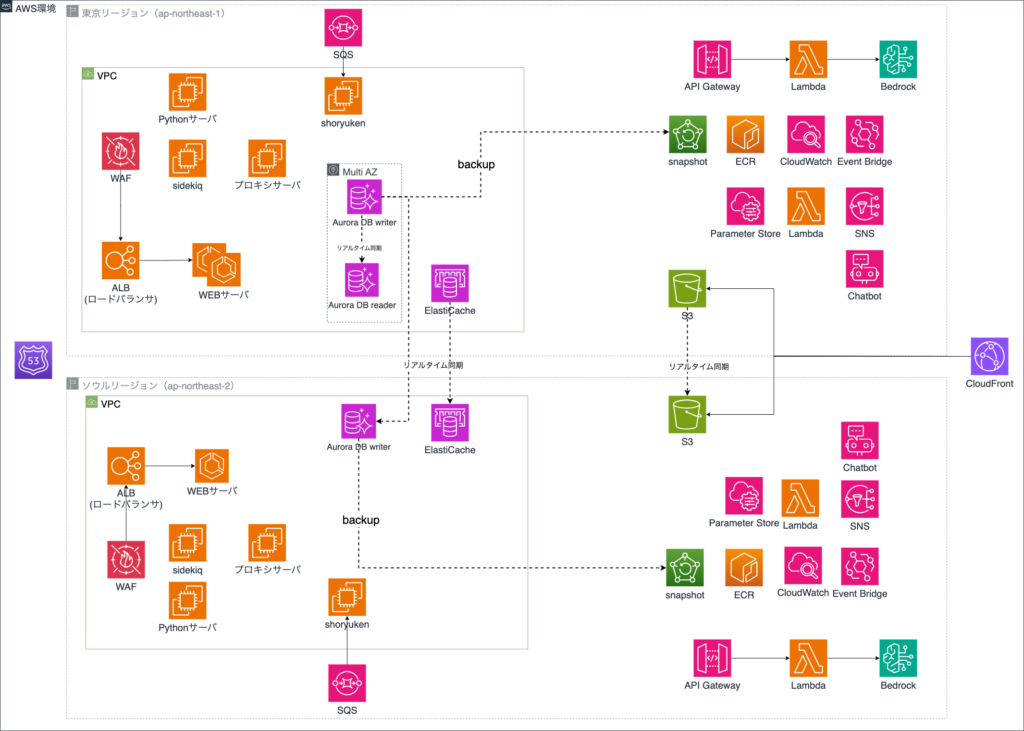
プロジェクトAのパイロットライト
- レプリケーションを取っているもの
- Aurora DB
- ElastiCache
- S3
- 停止状態のもの
- ECS
- EC2
障害が起きたら、
- DB, ElastiCacheをソウルリージョンへフェイルオーバー
- ソウルのECS, EC2を立ち上げ
- Route53(ドメイン)のルーティング先をソウルへ変更
- 各種設定変更
をおこない、ソウルリージョン稼働へ移す。
テストでは、すべてのリソースを切り替えるのに約3時間かかりました。
一部で設定漏れなどがありましたが、スムーズに進めば2時間程度で完了できる見込みです
DRテストの内容
- 移行テスト
- システム連携テスト
- バッチテスト
- 画面テスト
- 外部連携テスト
実際に東京リージョンでトラブルが発生したと仮定して、東京→ソウルの移行から、ソウル側での稼働まで約1週間を掛けてテストを行いました。
テストによってそれぞれ設定漏れなどがいくつか見つかりましたが、一番は外部連携が問題起こりがちでした。
実は今もまだ一部と連携できていないため、外部連携先へ確認を投げているところです。
DBの切り替えについて
Aurora Global Databaseの場合、以下の2つのフェイルオーバー方式があります。
| 項目 | スイッチオーバー | フェイルオーバー |
|---|---|---|
| 用途 | 計画的な運用・メンテナンス | 予期しない障害からの復旧 |
| 実行タイミング | 正常なシステム状態 | 障害発生時 |
| データ同期 | 完全同期を待機 | 同期を待たずに実行 |
| RTO | 数分 | 数分 |
| RPO | 0(データロスなし) | 数秒(レプリケーション遅延による) |
今回はスイッチオーバーでテストを実施しましたが、実際の障害発生時には、多少のデータ損失があってもフェイルオーバーを選択する方が適切と考えられます。
スイッチオーバーではデータ同期を行うため、同期元のデータベースが障害で停止している場合、復旧までに時間がかかる、あるいはスイッチオーバー自体が不可能になる可能性があります。
まとめ
ホットスタンバイ方式のDR対策では、本番と同等のインフラを常時維持する必要があるため、コストは2倍になりますし、DR対策はあくまで「保険」であり、どこまで投資するかは企業の判断に委ねられます。
そのため、ビジネス要件に応じた適切な落としどころを検討することが重要です。
また、DR環境を構築しただけで安心するのではなく、定期的なテストの実施や手順書のアップデートが重要になってくると考えられます。
参考サイト
出典:atlax blogs – Aurora Global Databaseを利用したDR自動切り替えについてhttps://atlaxblogs.nri.co.jp/entry/20240910
出典:Developers IO – [アップデート]Amazon Aurora Global Database は、(計画外の)フェイルオーバーができるようになりました
https://dev.classmethod.jp/articles/update-amazon-aurora-global-database-failover/




管理-300x158.png)


