
この記事について
本記事は、2022年10月に実施した社内勉強会資料の内容をもとに、社外向けに再編集したものです。
記載の情報は執筆当時のものであり、最新の仕様やベストプラクティスとは異なる可能性があります。
実装にあたっては、必ず最新の公式ドキュメントをご確認ください。
はじめに
SQLのパフォーマンスチューニングを考えた際、プログラマーの立場から
- 何に気をつければよいのか
- どんな点を意識してSQLを書けばよいのか
といったことをLT(=Lightning Talk)から学びたいと思いました。
さらに、学んだ内容を実際にRails上でどう書くかについても、備忘録として整理してみました。
参考①(Youtube):【技術セミナー】津島博士のパフォーマンス講座 ~SQLチューニング編
対象RDB:Oracle
アジェンダ
- SQLとオプティマイザ
- 実行計画
- 実行計画のチューニングプランナーが実行計画を立ててから実行する
仕組み(1:30〜
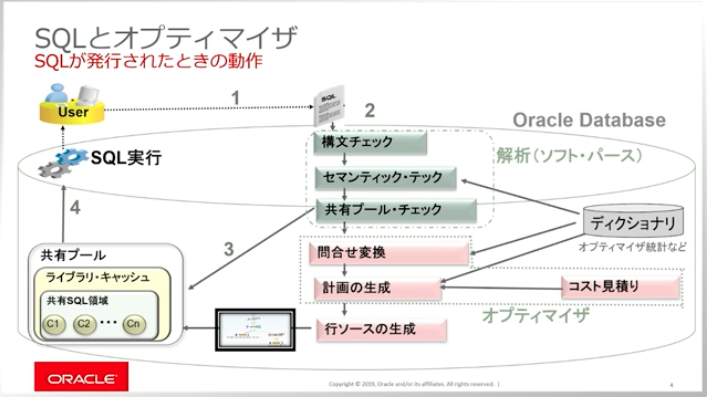
実行計画を作るのがオプティマイザの役割
実行計画とは(詳しくは動画をご覧ください)
- どのような順番で表を結合するかを選定する
→ このとき選定基準となるのが「見積行数」 - 見積行数を正しくするためにオプティマイザ統計を利用する
- 複数の表を結合する場合は、できるだけ早い段階で行数を減らせるよう結合順を選定している
- 見積行数(カーディナリティ)を早く減らして実行中の処理を少なくしようとする動きがある
- 実行時のプロセスでは、並列(パラレル)処理を使うかどうかを判断する
→ 軽い処理を大量に並列で実行するのか、重い処理を少数だけ実行するのかによって判断する
→ CPUやメモリ、キャッシュの使い方を決めるのにも統計情報が利用されるので、統計情報をうまく活用できるとよさそう
実行計画のチューニング(46:17~
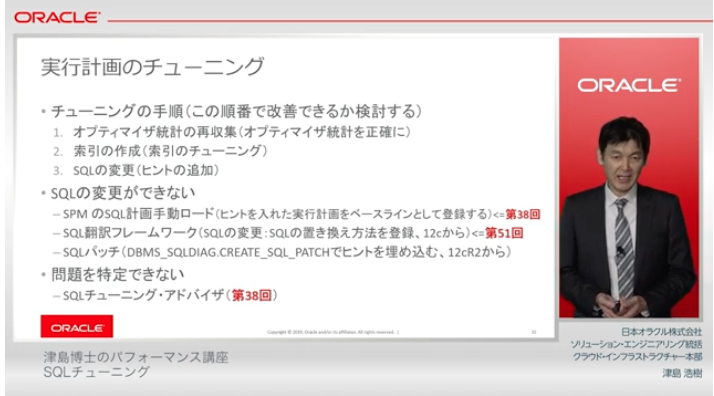
「簡単にできる事から順に試しましょう」
具体的な問題点となる実行計画と対策(49:46〜
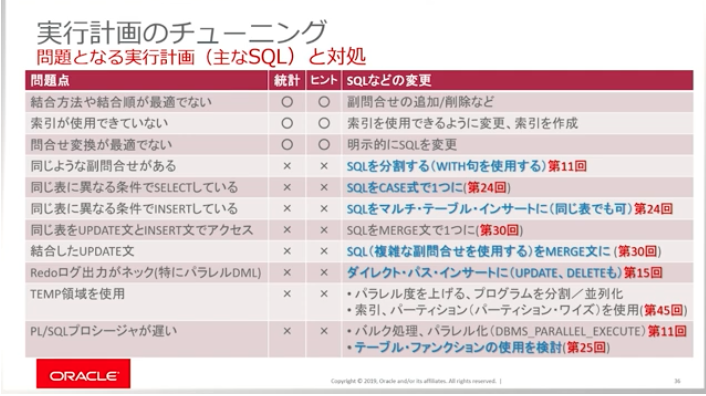
SQLを書き換える対策方法(1:01:08~

「繰り返し副問合せは WITH句で」
→RailsではActiveRecord::Base.connection.exec_queryを利用して生SQLを実行したり、VIEWを作成してModelに紐づける形でもチューニングできそうです。
基本的には、バッチ処理のような重い処理で使うことが想定されます。

「同じ表に異なる条件でのSELECTはCASE式に」
→ ActiveRecordで書くときはselectメソッドを利用して記載可能なので、試してみます。
[1] pry(main)> mems = Member.all.select("case status when 1 then 'status_1' when 2 then 'status_2' else 'other' end as status_name").limit(10)
Member Load (3.2ms) SELECT case status when 1 then 'status_1' when 2 then 'status_2' else 'other' end as status_name FROM "users" WHERE "users"."type" = $1 LIMIT $2 [["type", "Member"], ["LIMIT", 10]]
=> [#<Member id: nil, status_name: "status_1">,
#<Member id: nil, status_name: "status_2">,
#<Member id: nil, status_name: "status_1">,
#<Member id: nil, status_name: "other">,
#<Member id: nil, status_name: "status_1">,
#<Member id: nil, status_name: "status_1">,
#<Member id: nil, status_name: "status_1">,
#<Member id: nil, status_name: "status_1">,
#<Member id: nil, status_name: "status_1">,
#<Member id: nil, status_name: "status_1">]
[2] pry(main)> mems.map(&:status_name)
=> ["status_1", "status_2", "status_1", "other", "status_1", "status_1", "status_1", "status_1", "status_1", "status_1"]
[3] pry(main)> mems.count # countするとエラーになる
(0.9ms) SELECT COUNT(count_column) FROM (SELECT case status when 1 then 'status_1' when 2 then 'status_2' else 'other' end as status_name AS count_column FROM "users" WHERE "users"."type" = $1 LIMIT $2) subquery_for_count [["type", "Member"], ["LIMIT", 10]]
ActiveRecord::StatementInvalid: PG::SyntaxError: ERROR: syntax error at or near "AS"
LINE 1: ...2 then 'status_2' else 'other' end as status_name AS count_c...
^
from ~/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/activerecord-6.0.3.3/lib/active_record/connection_adapters/postgresql_adapter.rb:675:in `exec_params'
Caused by PG::SyntaxError: ERROR: syntax error at or near "AS"
LINE 1: ...2 then 'status_2' else 'other' end as status_name AS count_c...
^
from ~/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/activerecord-6.0.3.3/lib/active_record/connection_adapters/postgresql_adapter.rb:675:in `exec_params'
[4] pry(main)> mems.size # Array#sizeで対応しましょう
=> 10
select を使うと、countが使えなくなったりActiveRecordとしての扱いがしにくくなるので注意が必要そうです。
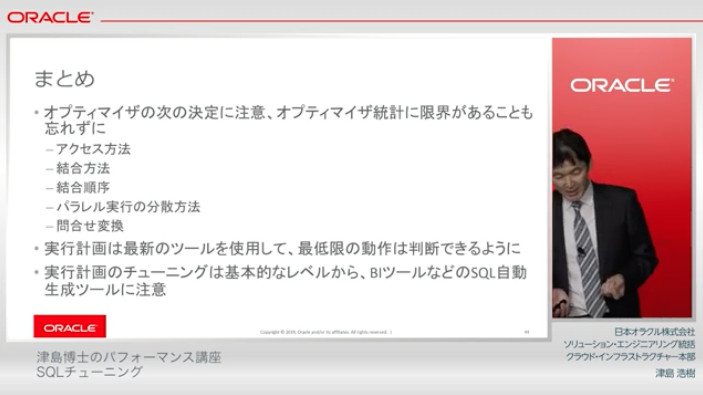
まとめ(1:04:47~
参考②(Youtube):【T3】SQL チューニングの基礎 高塚 遥
対象DB:PostgreSQL
アジェンダ
- SQLが実行される基本的な仕組みを知りましょう
- 遅い原因を把握しましょう
- できる手段を知りましょう
SQLが実行される仕組み(1:16〜
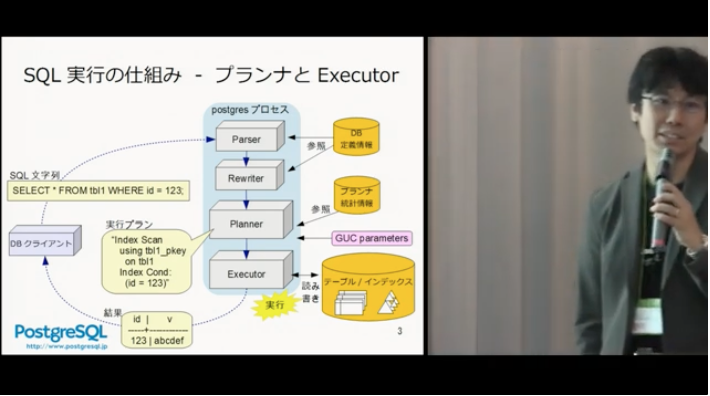
Oracleとだいたい似たような感じかな?という印象です。
PostgreSQLは、Update時に「Destroy & Insert」を行う仕組みなので、Vacuumが重要とのことです。
(最近は自動で実行されるようになったようで、設定で自動化もできるそうです。)
追記:Vacuumは処理が重いので、夜中等利用者数が少ない時間帯にバッチで実行したほうが良いとのことでした。
調べ方、結果の見方(14:40〜

explain(analyze, buffers)
<SQL文>「プラン要素」が想定通りになっているかチェック(特にテーブルを結合する際)。
見積もりコストにはFile IOも含まれるため、メモリ上にデータがある場合はコストが下がる。
「計画ノード」と呼ばれる破線で囲まれた部分が、意図したものになっているかを確認すると良い。
この画面の詳細な見方についてのまとめ
出典:PostgresWeb – ポスグレウェブ – 【PostgreSQL】Explainの見方(analyze , cost , scan , sort)についてのまとめ
https://postgresweb.com/post-4047
紹介①(Youtube):【T2】実際に使うSQLの書き方 徹底解説 曽根 壮大(そね たけとも、そーだい)
関連資料:https://speakerdeck.com/soudai/pgcon21j-tutorial
15枚目(https://speakerdeck.com/soudai/pgcon21j-tutorial?slide=15)

オプティマイザの話と合わせると、上記スライド内に記載の順番の上流側で十分に件数を絞り込めれば、パフォーマンスは向上しそうです。
RailsのActiveRecordでは scope で where を書いて絞り込むのも良いですが、それが遅い場合は joins で on の条件を指定してあげると速くなるかもしれません。
特に、結合する側のテーブルのデータ量が多い場合は、結果の行数が増えないよう注意が必要です。
(ON句の条件が抜けると重複データが発生し、バグにつながる可能性も…)
ただし、可読性は下がりがちなので乱用は注意したほうが良さそうです。
「データーベースの寿命はアプリケーションより長い」
=長く使えて変更に強いDB設計を考えるべき、とのことでした。
紹介②(ブログ):Agile Journey – アジャイル開発とデータベース設計 – 変化に対応するシンプルな実装のために必要なこと
出典:Agile Journey – アジャイル開発とデータベース設計 – 変化に対応するシンプルな実装のために必要なことhttps://agilejourney.uzabase.com/entry/2022/07/28/103000
少し極端かなとも思いますが、確かに仕様変更には強そうです。
最後のは若干毛色が違う気もするのですが、設計段階からパフォーマンスチューニングを意識していると感じましたので、紹介として記載します。
追記
実際のプロジェクトで発生した不具合を調査し、原因を突き止めたものの中から「他のプロジェクトでも発生しうる事例」と思ったものを共有いたします。
バグ1:検索結果が重複して表示される(ページング内で発生)
・原因:inner join の ON 句で条件が十分に絞り込めておらず、行数が増えてしまっていた
バグ2:検索結果が重複して表示される(ページングをAjaxで取得し追加表示すると発生)
・原因:ページングのたびにソート順を取り直していたことに加え、ソートキーが裏で更新され続けていた。
その結果、1ページ目で10番目にいたデータが、2ページ目を表示した時点では11番目に移動してしまい、
同じデータが何度も表示されているように見えていた。
→ 1ページ目で全ページ分のソート順をキャッシュに保存し、2ページ目以降はキャッシュを参照するように修正することで解決
まとめ
- SQLチューニングでは オプティマイザと実行計画 の仕組み理解が必須
- 不要な重複や結合条件の不足は 典型的な遅延原因
- RailsのActiveRecord 経由でデータ取得、 SQL次第で型が変化するので注意
- PostgreSQL では Vacuum 運用が性能維持に重要




管理-300x158.png)


